Face Robot では、オーディオ ファイルからリアルなアニメーション データを作成することができます。Face Robot では、国際音声記号(IPA)の標準規定に従う英語の 38 の音素と日本語の 23 の音素を識別し、音声認識技術によってこれらの音素がオーディオ ファイルのどこに位置するかを自動的に判断します。インポートしたライブラリの口形素が、対応する各音素に自動的にマップされます。
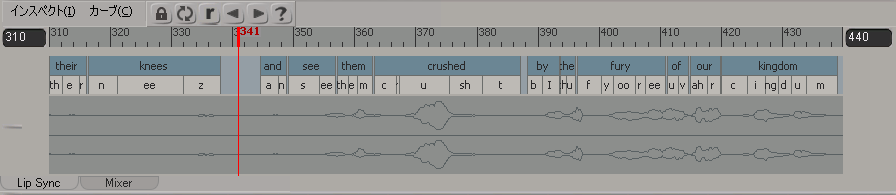
口形素のアニメーションは、頭のモデルのミキサにロードされるスピーチ クリップに保存されます。このクリップには、唇、顎、および舌のアニメーション コントロールにあるリップシンク アニメーションが含まれます。オーディオ クリップは、このトラック上にロードされ、スピーチ クリップに相対的にリンクされるので、どちらか一方が移動しても同期するように設定されています。詳細については、「リップシンク アニメーションをブレンドする」を参照してください。

Face Robot では、次のオーディオ ファイル形式がサポートされています。詳細については、「サポートされているオーディオ ファイル形式」を参照してください。
オーディオ ファイルをロードする前に、使用するオーディオ ファイルの形式が現在サポートされているかどうかを確認してください(前述のリストを参照)。また、オーディオ ファイルの台詞が書き出されたテキスト ファイルも必要になります。このテキスト ファイルは、オーディオ ファイルと同じ名前になりますが、拡張子には .txt などが使用されます。オーディオ ファイルの台詞のテキストを使用することにより、より自然なリップ シンクを作成することができます。
オーディオファイルの台詞を書き起こしたテキストファイルがない場合は、まずオーディオファイルと同じフォルダに同じ名前で空の.txtファイルを作成し、[LipSync(リップシンク)]ダイアログボックスに直接テキストを入力して保存します。
[Library(ライブラリ)]パネルから[リップシンク](LipSync)  [リップシンクの作成](Create LipSync)を選択します。
[リップシンクの作成](Create LipSync)を選択します。
[LipSync(リップシンク)]ダイアログ ボックスが開いたら、リップシンクの作成に使うオーディオ ファイルとテキスト ファイルの[言語](Language)を、英語と日本語の中から選択します。
[オーディオ](Audio)のブラウズボタン(...)をクリックし、オーディオファイルを選択します。
オーディオ ファイルに対応するテキスト ファイルが同じフォルダ内に存在する場合は、それが自動的にロードされます。ここで、誤字?脱字があればそれを修正し、[保存](Save)ボタンをクリックしてロードする前に更新します。
テキスト ファイルがオーディオ ファイルとともに自動的にロードされない場合は、[テキスト](Text)のブラウズボタン(...)をクリックして、テキスト ファイルを選択するためのブラウザを開きます。
オーディオファイルのテキストファイルがない場合は、まずオーディオファイルと同じフォルダに同じ名前で.txtファイルを作成します。次に、その.txtファイルをロードし、台詞をこのテキストボックスに入力します。[保存](Save)ボタンをクリックすると、入力した台詞が空の.txtファイルに書き込まれます。
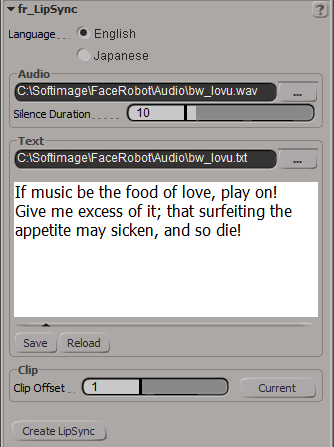
スピーチ クリップを作成する準備が整ったら、[Lip Sync(リップシンク)]ダイアログ ボックスで[リップシンクの作成](Create LipSync)ボタンをクリックします。
オーディオ ファイルとテキスト ファイルが解析され、音素が作成され、それが Lip Sync ビューのトラックに挿入されてビューポートの下に表示されます。「リップ シンク ビュー」を参照してください。
スピーチ クリップは、頭のモデルのミキサに作成されます。表示された[Speech Blend(スピーチ ブレンド)]プロパティ エディタで、そのクリップの唇、舌、および顎のアニメーションがブレンドされる方法を設定することができます。「リップシンク アニメーションをブレンドする」を参照してください。
アニメーションで再生して、台詞に沿って口がどのように動くかを確認します。より良い音声を求めてすべてのフレームを再生するよりも、リアルタイムで音声を再生してください。再生する音声を設定する詳細については、「オーディオを再生する」を参照してください。
また、フリップ ブックを作成して、最初の結果を解析することができます。「 フリップブックでアニメーションをプレビューする」を参照してください。
音素の変更準備が整ったら、Lip Sync ビューを開きます。「リップ シンク ビュー」および「音素を調整する」を参照してください。