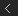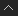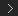The nodes in the Execution category can be used to control program flow in ICE trees.
To understand how a tree is evaluated, it helps to think of it as a two-way process. Requests for data are pushed upstream along execute-type connections from right to left. Each port of the root node begins afresh by requesting a full set of data. As the request for data gets passed along, If and Select Case nodes may send requests for different members of a data set down different sub-branches. As a result, the data that is being requested in a specific branch may not be the full set.
Once the requests for data have been pushed up the tree to the leaf nodes, the data values flow back down the connections from right to left towards the root. These data values may be filtered, either explicitly using a Filter node (see Automatic Filtering) or automatically under certain conditions (see Validating Data). The members of a data set that have been filtered out are specially flagged and ignored by downstream nodes.
Conditional Execution: If and Select Case
The If and Select Case nodes are used to evaluate different subtrees according to a condition.
They both accept either execute or data-type connections. You can connect execute ports to their inputs in order to execute different subtrees for different members of a data set, or you can connect other data types to pass different values downstream.
The If node evaluates one of two branches, based on a Boolean Condition. If the If node's Condition has been filtered out for a member of a data set, neither branch is evaluated for that member and the result is filtered. The If node can be used in a similar way to the Filter node — see Automatic Filtering.
The Select Case node evaluates one of an arbitrary number of branches, based on the value of an integer Condition. If no branch has been specified for a specific integer value, it returns the result of its Default branch. If the Condition value has been filtered out for a member of a data set, no branch is evaluated for that member and the result is filtered. The Select Case node is particularly useful in compounds, where you can assign strings to predefined integers and select them from a drop-down list — see Setting Predefined Values.
The If and Filter nodes can be used to apply values to certain members of a data set. In many situations, they can be used almost interchangeably. For example, the following two trees both set particles' Color to red if Age is greater than 10.
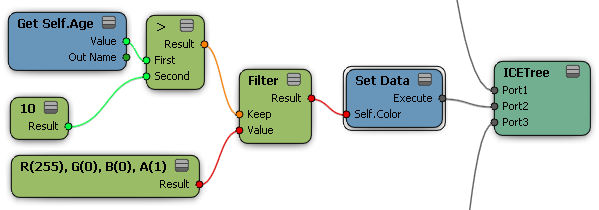
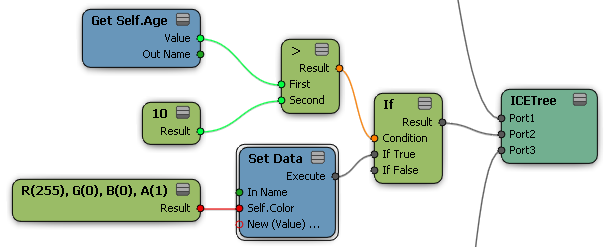
The difference between the Filter and If nodes is that Filter filters out values that do not meet the Keep condition so that they are ignored by upstream nodes. In contrast, the If node has branches for If True and If False — if there's an execute-type port with nothing connected then nothing will happen, but if there's a data-type port then a value will be passed downstream whether the Condition is true or false.
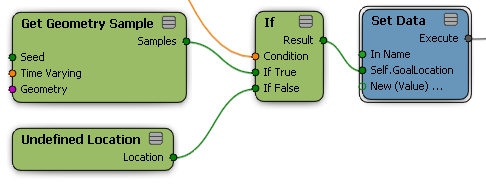
One possible use of Filter is to create a compound that processes a data set in a general way without using Set Data to write values of specific attributes. On the other hand, you cannot attach execute-type connections to Filter's input port, and you cannot use Filter to supply data where Keep is false. For example, if you want to supply Undefined Location where a condition is not met, you must use an If node as in the following illustration:
Some values in a data set may get filtered out automatically without using a Filter node explicitly. This will happen in the following cases:
If you use a Get Data node to return PointPosition or other attributes from an undefined location, the value is filtered. For example if you use Get Closest Location with a Cutoff Distance, members of the data set that are too far away from the specified geometry return Undefined Location. If you then get the PointNormal, those members of the data set are filtered out.
When you use the Basic Collide node, Hit Frame Fraction is filtered out when Hit is false.
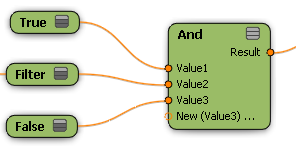
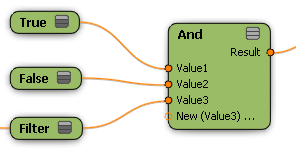
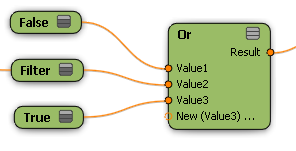
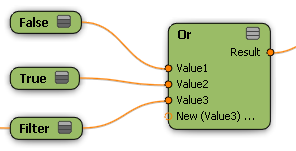
The And and Or nodes use "short-circuit" logic to evaluate their inputs. This means that for each member of a data set, the And node stops evaluating its inputs as soon as it encounters a non-true value. The first non-true value is passed to the nodes downstream. When one or more of the input data sets contain members that have been filtered out, the first non-true value could be either "false" or "filtered out" depending on the order in which the inputs are connected.
Similarly, the Or node returns the first non-false value among its inputs.
You can take advantage of this short-circuit logic by placing easy-to-evaluate conditions first among the inputs for And and Or nodes in order to save unnecessary processing costs. For example, put an "Enabled" toggle before a complex calculation.
The While and Repeat nodes can be used to "loop" or repeat a branch of a tree.
If the Condition of a While node has been filtered out for a given member of a data set, then no processing is done for that element. Similarly, if the Iterations of a repeat node have been filtered out, no processing is done for that element.
If you need to get the iteration number within the loop, store it in a custom attribute.
There are several ways to validate data as it flows downstream.
You can use the First Valid node to supply alternative values. It will return the value from the first connected branch that is not in error (displayed as red nodes). The First Valid node itself is considered to be in error and appears red only when all of its inputs are in error. The First Valid node only considers structural problems in the tree, such as undefined references — it does not consider runtime errors such as division by zero.
You can use the Is Valid Location node to verify that a location is valid, that is, that the location exists on any geometry in the scene. You can use the Is on Geometry node to verify that a location exists on specific geometric objects. See Undefined Location.
Some nodes, including Divide by Scalar, Invert, Modulo, and Log, have Valid output ports that return false in the case of invalid operations like division by zero or inverting a singular matrix. You can use the Valid port in combination with If or Filter nodes to filter the problematic results.
You can also use Filter and If nodes to filter problematic values before passing them downstream, For example, you can test whether a divisor is equal to zero before dividing, or use the Is Singular node to test whether a matrix is invertible before inverting.
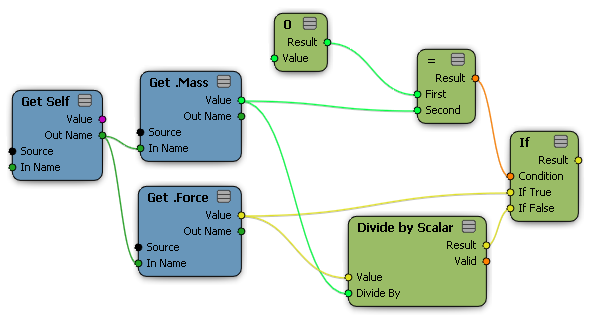
This tree tests whether mass = 0 before using it to compute acceleration = force / mass.
The Execute node evaluates all execute-type connections that are plugged into it. This is useful for performing actions such as setting data at tree locations other than the root, for example, in a loop or in a branch of an If node. The Execute node is also useful for collecting multiple execute-type connections into a single output port in a compound.
The Pass Through node simply passes along anything connected to it completely unchanged. It is mainly used in compounds for connecting an exposed input port to multiple internal nodes.
In general, you cannot combine data from different contexts. This is because the data is usually incompatible. For example, different objects usually have different numbers of points, and there is no way to add or compare data sets of different sizes. There is one exception — when objects are duplicates — and in this case you can use the Switch Context node.
The Switch Context node simply "decontextualizes" the upstream branch so that it can be combined with any other context. The other context gets propagated to the downstream nodes. Both data sets must have the same size or the branch will not be evaluated.
One possible use of the Switch Context node is to create a simple shape mixer that interpolates the PointPosition values of one object between those of other objects. However, you won't get sensible results unless the topologies are identical.