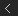One of the most common threading problems is the race condition, where two threads attempt to modify the same data. Modifying a data element is not usually an atomic operation, meaning it is possible for both threads to read the value, then update it, then write it. In such cases one of the edits will be overwritten by the other. Race conditions can be extremely hard to detect as they may happen only very rarely, and be hard to reproduce. Tools such as Intel's ThreadChecker are good for catching race conditions, both ones that actually happen and those that could potentially happen.
Race conditions obviously lead to incorrect results. There are other more subtle problems that can occur in threaded code. An example is precision differences in floating point arithmetic. With reduction operations, where values are accumulated in different numbers of threads and then summed, the number of threads can affect the final result since the roundoffs are different:
#pragma omp parallel for reduction(+: sum)
for ( int i = 0 ; i < n ; i++ ) sum += x[i]*y[i];
This can be a significant effect for simulations, where small differences can accumulate over time. Below are two images from an initial threaded implementation of the Maya fluids solver that in one place called code similar to the above. The only difference between the runs is the number of cores on the system, and so the number of threads being used in the solver. Although neither result is incorrect, the difference in appearance due to differences in roundoff is quite dramatic:


There are a couple of ways to avoid this. One is to temporarily use higher precision, for example, going from floats to doubles during the threaded computation. The idea is that the threading benefit is greater than the performance hit of higher precision computations. Another way is to break the data into a number of chunks that is fixed at compile time, and allocate those chunks to threads at runtime, then accumulate the sums in a consistent order. This ensures the size of a chunk never changes, so the final sum should always be identical.
Some C/C++ library functions are not threadsafe as they maintain internal state. Examples are STL containers (even reads of STL containers may not be threadsafe in some cases), C functions like strtok(), and many built-in random number generators. Care must be taken if any of these are called from threaded code. TBB provides threadsafe containers as an alternative to STL, and there are threadsafe implementations of many C functions which are identified with an _r suffix (for reentrant) on Linux and OSX, or an _s suffix on Windows, for example, strtok_r() is a threadsafe version of strtok(), strtok_s() is an equivalent threadsafe function on Windows. Unfortunately there are no cross-platform standards for these threadsafe functions at the moment.
Amdahl's law is an observation that for a fixed problem size, performance scaling has diminishing returns as thread counts increase because the serial portion of the code eventually dominates, leading to a ceiling on scalability.
Gustafson's observation is that usually increasing thread counts are used to address larger problems, so rather than a fixed problem size it is better to think in terms of a fixed runtime. In such cases, scaling can continue to increase indefinitely provided that the fraction of work in parallel versus serial code increases with the problem size.
For applications like Maya, we are closer to the second case than the first, so there is hope for increasing scalability over time for well written algorithms. Below is an example of the fluids solver showing increasing problem size leads to improved scaling.
There is an overhead of around 10k cycles to wake up a thread pool. Therefore, any calculation that will take close to this number of cycles to evaluate is not worth threading. For cases where the trip count can vary wildly, and the loop is called many times, it may be worth explicitly providing a lower cutoff to avoid a performance hit. The following diagram shows performance of threaded and unthreaded code with small model sizes for one of Maya's deformers. At the smallest sizes threading overhead dominates, and single threaded code is actually faster than multithreaded code. Therefore threading was disabled below the crossover point on this graph.
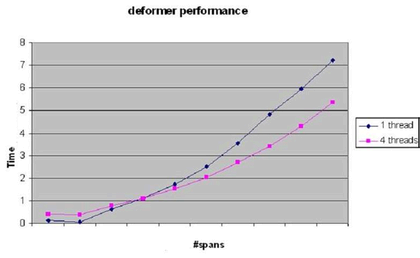
Another scalability challenge is that locks get increasingly expensive with higher thread counts, so it is worth avoiding locks if at all possible, or at least being sure to re-profile an application when running on a machine with more cores than previously used. An algorithm that scales well to 4 cores may not scale well, or may even slow down, when going to 8 cores.
Some loops have very different work per iteration. For example a tool that operates on a subset of vertices of a mesh, or a fluids solver working on a volume that has some empty cells, will have some iterations that have little or no work to do. Simply splitting the number of elements equally among threads will be a poor choice for such cases, and it may be worth investigating algorithms and implementations that distribute work more uniformly, for example OpenMP's guided or dynamic scheduling, or TBB.
Processor caches work by reading requested data into local caches. However it is not just the actual data that is loaded, but an entire cache line of data around the data item being read. A cache line is usually 64 bytes in size, but it is not guaranteed to be this value.
False sharing is a situation where multiple threads are reading from, and writing to, variables that are situated close enough in memory that they would reside on the same cache line when read into the cache. When one thread writes to one such variable, the entire cache line is read into the processor cache, and when a different thread attempts to modify the other data element the data must be written from the first processor cache out to a lower level cache or to main memory and then loaded into the other processor cache. This can lead to a ping-pong situation, where a chunk of data is continually bouncing between processor cores, and can clearly cause a significant performance hit.
The plug-in threadedBoundingBox,supplied with Maya, illustrates the cost of false sharing and shows how to avoid it. In this plug-in multiple threads are used to compute one element of a bounding box. Each thread computes a float value representing the minimum X value of the bounding box for a subset of the points. The computed value is written into an array. The computation is run in different ways, single threaded and then multithreaded varying the spacing of the array elements used to hold the output results:
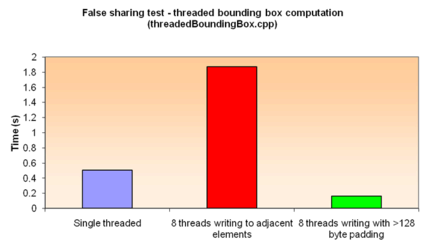
In the first test case, each thread writes to an adjacent array element. On a machine with up to 8 cores running separate threads, all threads are likely to write to the same cache line, triggering severe false sharing, since each element is only 4 bytes in size. In such cases performance is actually significantly worse than the unthreaded implementation.
In the second test case padding is added between active array elements to ensure each value will always be on a separate cache line. In this case, performance is much better. The padding is computed by first querying the cache line size for the current processor. In Maya, there is a new API method called MThreadUtils::getCacheLineSize() that will return the correct value at runtime for the host processor. Using this method is the safest way to ensure the code is well behaved for cache line access and also remains well behaved in future with processors that may have larger cache line sizes.
Processors such as the Core i7 (Nehalem) have hyperthreading, where a single physical core is treated as two logical cores and two threads of execution can be run on the same physical core. This can provide additional performance but will not provide the same benefit as two physical cores since many core resources must be shared by the threads. In some cases it may lead to poorer performance than a single thread.
By default, threading APIs like OpenMP and TBB will create one thread per logical core, so will make use of hyperthreading. It is important to test the effect of hyperthreading on your code. If you find it is hurting performance and you choose to run fewer threads than there are logical processors, you may need to check the operating system scheduling behavior. Older operating systems like Windows XP do not necessarily schedule tasks to threads in the optimal way when hyperthreading is present, and sometimes two threads can be running on one core while another core is idle. In such cases it may be best to disable hyperthreading in the system BIOS.