[Execution]カテゴリのノードは、ICE ツリーのプログラム フローを制御するのに使用できます。
ツリーの評価方法を理解するには、これが 2 つの処理から成り立っていることを考えるとよいでしょう。データの要求は、右から左に向かって実行タイプの接続を上流にプッシュされます。ルート ノードの各ポートは、データのフル セットを要求することによって、一から開始されます。データの要求が渡されると、[If]および[Select Case]ノードは、異なるサブブランチのデータセットの異なるメンバに対して要求を送ります。その結果、特定のブランチにある要求されたデータはフル セットにならない場合があります。
データの要求がツリーのリーフ ノードにプッシュされると、データ値はルートに向けて右から左に接続を逆に流れていきます。これらの値は、明示的に[Filter]ノード(「自動フィルタリング」を参照)を使用するか、特定の条件を設定して自動的に(「データを検証する」を参照)フィルタリングすることができます。フィルタリングされたデータセットのメンバは、特別なフラグが付き、下流ノードでは無視されます。
[If]ノードおよび[Select Case]ノードは、条件に従って、さまざまなサブツリーを評価するのに使用されます。
どちらも実行またはデータタイプの接続のいずれかを受け入れます。実行ポートをそれらの入力に接続して、データ セットのさまざまなメンバのさまざまなサブツリーを実行したり、他のデータ タイプを接続して、さまざまな値を下流に渡すことができます。
[If]ノードは、ブールの条件に基づいて、2 つのブランチのいずれかを評価します。[If]ノードの[Condition]でデータ セットのメンバがフィルタリングされている場合は、メンバのどちらのブランチも評価されず、結果がフィルタリングされます。[If]ノードは、[Filter]ノードと同様の方法で使用できます(「自動フィルタリング」を参照)。
[Select Case]ノードは、条件の整数の値に基づいて、任意の数のブランチの 1 つを評価します。特定の整数値にブランチが指定されていない場合は、デフォルトのブランチが結果として戻されます。[Condition]値がデータ セットのメンバでフィルタリングされてる場合、そのメンバに対してブランチは評価されず、結果はフィルタリングされます。[Select Case]ノードは、事前定義された整数に文字列を割り当て、ドロップダウン リストからそれらを選択できるコンパウンドで特に便利に使用できます(「定義済みの値を設定する」を参照)。
[If]ノードと[Filter]ノードは、値をデータセットの特定のメンバに適用するのに使用できます。これらのノードは、多くの状況で、ほとんど区別なく使用できます。たとえば、次の 2 つのツリーはどちらも、パーティクルの経過時間が 10 より大きい場合に、パーティクルの[カラー]を赤に設定します。


[If]ノードと[Filter]ノードの違いは、[Filter]ノードが[Keep(保持)]条件に一致しない値をフィルタリングして上流のノードで無視されるようにするのに対して、 [If]ノードには[If True]および[If False]のブランチがあることです。[If]ノードに実行タイプのポートがあり、何も接続されていない場合は、何も発生しませんが、データタイプのポートがある場合は、[Condition]のオン/オフに関わらず、値は下流に渡されます。
たとえば、[Filter]は、特定の属性値を記述するのに[Set Data]を使用せずに、一般的な方法でデータを処理するコンパウンドの作成に使用できます。一方、実行タイプの接続を[Filter]の入力ポートにアタッチすることや、[Filter]を使用して[Keep(保持)]がオフになっているデータを指定することはできません。たとえば、条件が一致しない[Undefined Location](未定義の位置)を指定したい場合は、下図に示すように[If]ノードを使用する必要があります。

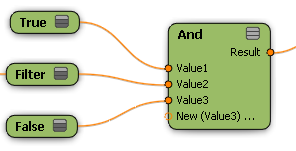
[And]および[Or]ノードは、「短絡」論理を使用して入力を評価します。つまり、データセットの各メンバについて、[And]ノードは true 以外の値を検出すると入力の評価を停止します。最初の true 以外の値は、下流のノードに渡されます。1 つまたは複数の入力データセットにフィルタリングされたメンバが含まれる場合は、入力が接続された順に応じて、最初の true 以外の値は「false」または「フィルタリング」のいずれかになります。
|
[Filter]は、常に true であるものとして評価されない最初の入力です。結果のデータ セットでは、一部のメンバは false になり、一部はフィルタリングされます。 |

|
[False]は、true ではない最初の入力です。データ セット全体の結果は、false になります。[Filter]ノードは評価されません。 |
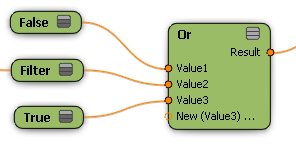
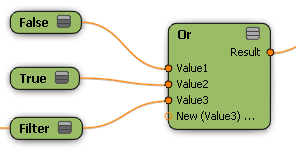
同様に、[Or]ノードは、入力内の最初の false 以外の値を戻します。
|
[Filter]は、常に false であるものとして評価されない最初の入力です。結果のデータ セットでは、一部のメンバは true になり、一部はフィルタリングされます。 |
|
[True]は、false ではない最初の入力です。データ セット全体の結果は、true になります。[Filter]ノードは評価されません。 |
この短絡論理は、不要な処理コストを削減するために、簡単に評価できる条件を[And]および[Or]ノードの入力に設定することで活用できます。たとえば、複雑な計算の前に[Enabled]のトグルを追加します。
[While]ノードと[Repeat]ノードは、ツリーのブランチを「ループ」またはリピートするのに使用できます。
[While]ノードの[Condition]でデータセットの指定されたメンバがフィルタリングされている場合は、そのエレメントの処理は実行されません。同様に、リピートノードの反復がフィルタリングされている場合も、そのエレメントの処理は実行されません。
下流に流れるときにデータを検証するには、いくつかの方法があります。
[First Valid]ノードを使用して、代替値を指定できます。このノードは、エラーではない(赤いノードに表示されているものではない)最初に接続されたブランチから値を戻します。[First Valid]ノード自体は、エラーに存在するものとしてみなされ、すべての入力がエラー状態のときにのみ赤く表示されます。[First Valid]ノードでは、未定義のリファレンスなどのツリーの構造問題だけが考慮され、ゼロによる分割などのランタイム エラーは考慮されません。
[Is Valid Location]ノードを使用して、位置が有効であること(位置がシーンの任意のジオメトリに存在していること)を検証できます。[Is on Geometry]ノードを使用して、位置が特定のジオメトリ オブジェクトにあることを検証できます。「Undefined Location」を参照してください。
[Divide by Scalar]、[Invert]、[Invert]、[Log]などの一部のノードには、ゼロによる分割や 1 つの行列の反転など、無効な操作の場合に false を戻す[Valid]ポートがあります。[If]ノードまたは[Filter]ノードと共に[Valid]ポートを使用して、問題のある結果をフィルタリングすることができます。
また、[Filter]ノードおよび[If]ノードを使用して、問題がある値を、下流に渡される前にフィルタリングすることができます。たとえば、除数が割られる前にゼロになっていないかをテストしたり、[Is Singular]ノードを使用して、行列が反転前に反転可能であるかをテストすることができます。
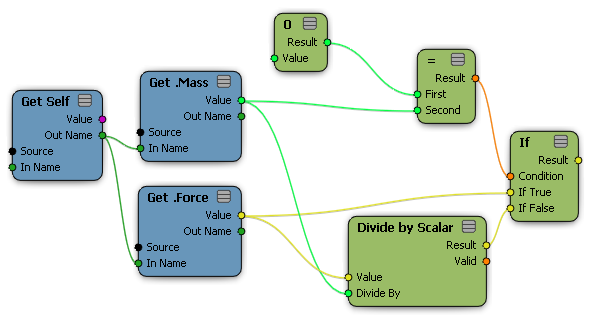
[Execute]ノードは、そこの接続されている実行タイプのすべての接続を評価します。この機能は、たとえば、ループや[If]ノードのブランチなどで、ルート以外のツリーの位置でデータを設定する場合などに便利です。また、[Execute]ノードは、複数の実行タイプの接続をコンパウンドの 1 つの出力ポートに収集する場合にも役立ちます。
通常は異なるコンテキストのデータは結合できません。これは、データが通常は互換性がないためです。たとえば、異なるオブジェクトには通常は異なる数のポイントがあり、サイズの異なるデータ セットを追加したり比較したりすることができません。ただし、これには例外が 1 つあります。オブジェクトが複製されたものである場合は、[Switch Context]ノードを使用できます。
[Switch Context]ノードは、上流のブランチを「脱文脈化」させるので、他のコンテキストと結合できるようになります。他のコンテキストは、下流のノードに継承されます。両方のデータセットには、同じサイズが設定されている必要があります。サイズが違うと、ブランチは評価されません。
[Switch Context]ノードの使い方として、1 つのオブジェクトの[PointPosition]値を他のオブジェクトの値の間で補間するシンプルなシェイプ ミキサを作成することが考えられます。ただし、トポロジが同じ場合以外は、適切な結果が得られません。





