The Voice device settings contain controls to let you set thresholds, specify voice parameters, and set gender for your voice, as well as save and remove voice setups.
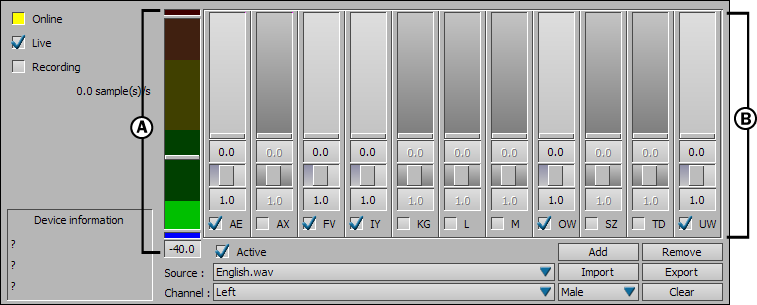
Voice device settings A. Threshold meter B. Sound parameter
Threshold meter and Threshold slider
The Threshold meter shows a graphical representation of the audio input in the Voice device. It rises as the audio input gets louder, and registers at zero when there is no sound.
The Threshold slider lets you set a Threshold level to compensate for noise in your audio. See Setting an audio threshold .

A. Threshold meter B. Threshold slider
When the sound level falls lower than the Threshold slider, the Voice device does not consider the signal to be speech and sets all phoneme values to zero.
Lets you specify your audio source. You can use the Voice device with live audio input and recorded .wav files.

Source menu
Opens the Voice Parameter Selection dialog box, letting you add sound parameters to the Voice device. See Voice Parameter Selection dialog box.
Removes the selected sound parameter from the Voice device. See Removing sound parameters.
Use the Gender menu to precisely analyze spoken vowels. See Specifying gender in the Voice device.

Voice device settings A. Gender menu
The Voice device’s sound parameters include phonemes and various instruments that measure sound properties.
Each sound parameter has a value representation, Filter slider, Weighting value, and Active button. By adjusting values in the sound parameters, you can do the following:

Sound parameter A. Phoneme value representation B. Filter slider C. Weighting value D. Active option
| Option | Description |
|---|---|
| Phoneme value | The phoneme values display in two forms on each sound parameter: as sliders, and as numerical values. Phoneme values display information taken from the audio input, so you cannot modify them in the Voice device. |
| Filter slider | Adjust the Filter sliders to smooth phoneme transitions. See Smoothing phoneme transitions. |
| Weighting value | The Weighting value on each sound parameter dictates the amount of emphasis each phoneme reflects in the talking model. See Refining a model’s face movements. |
| Active | Activates the individual sound parameter. |